5. 이미지 처리 능력이 탁월한 CNN
1960년대에 신경과학자인 데이비드 휴벨과 토르스텐 비젤이 고양이에게 간단한 이미지들을 보여주고 뇌가 어떻게 반응하는지 살폈다
그 결과 서로 비슷한 이미지들은 고양이 뇌의 특정 부위를 지속적으로 자극하고, 서로 다른 이미지는 서로 다른 부위를 자극한다는 사실을 발견함.
-> 이미지의 각 부분에 뇌의 서로 다른 부분이 반응하여 전체 이미지를 인식!
-> 이미지가 머리에 들어올 때 특징을 추출하는 부분이 있다.
-> CNN(Convolutional Neural Network)
CNN : 합성곱 신경망. 이미지와 비디오 같은 영상 인식에 특화.
병렬 처리가 쉬워 대규모 서비스에 적용 가능. 최근에는 이미지뿐 아니라자연어 처리, 추천 시스템에도 응용됨.
5.1 CNN 기초
- 컴퓨터가 어떤 식으로 이미지를 학습하는가 자세히 알아보기
- 컨볼루션이 무엇인지
- 이미지 특징을 추출하는데 사용하는 컨볼루션 계층 몇 가지 알아보기
5.1.1 컴퓨터가 보는 이미지

왼쪽이 우리가 보는 이미지이면, 오른쪽이 컴퓨터가 인식하는 이미지이다.

우리는 신경망에 이 이미지를 인식시키기 위해서 array 형태로 만들어야한다.
당장 18픽셀짜리만해도 이렇게 수가 많은데, 실제 사용되는 고화질 이미지를 생각하면 데이터 개수는 100만개가 훌쩍 넘고, 원활한 학습을 위해 이미지 처리(크기 조절, 좌우 대칭, 위치 변환 등)을 모두 거쳐 학습시키는 것은 사실상 불가능하다.
5.1.2 컨볼루션
목적 : 인간처럼 계층적으로 인식할 수 있도록 단계마다 이미지의 특징을 추출하는 것.
-
Convolution : 합성곱. 필터를 적용할 때 이미지 왼쪽 위에서 오른쪽 밑까지 밀어가며 곱하고 더하는 과정.
- CNN = 이미지를 추출하는 필터를 학습함. 필터가 하나의 신경망.
- Convolution Neural Network : 컨볼루션을 하는 인공 신경망.
라고 책에서 적혀있는데 사실 잘 와닿지 않아 좀 더 찾아봤다.
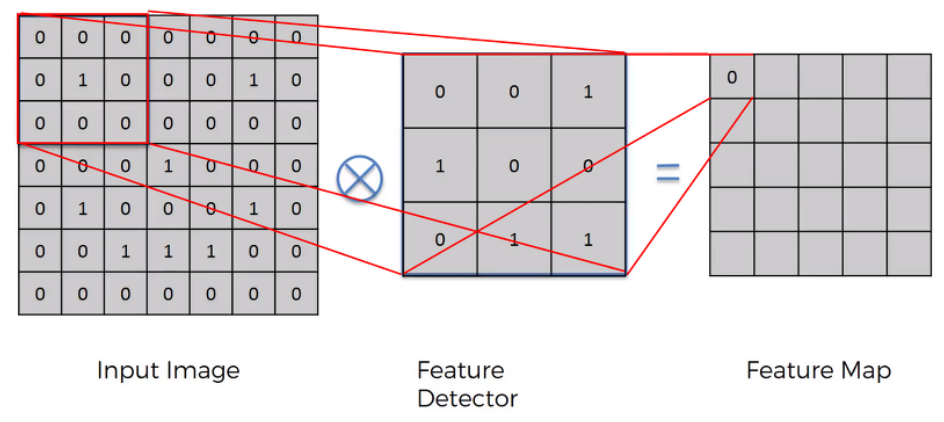
입력 이미지가 들어왔을 때, Feature 를 감지할 수 있는 Detector가 존재한다. 이 Detector는 Input Image의 모든 영역을 훑으면서 특정 Feature를 뽑고, 이를 바탕으로 해당 입력에 대한 Feature Map을 그리게 된다.
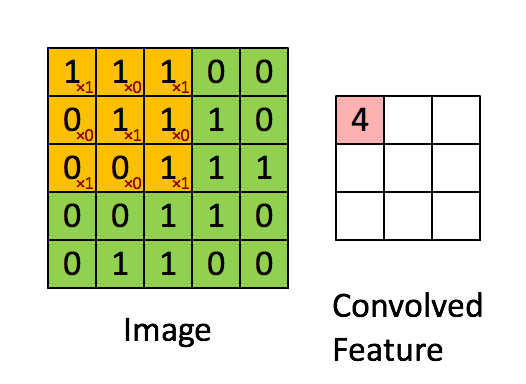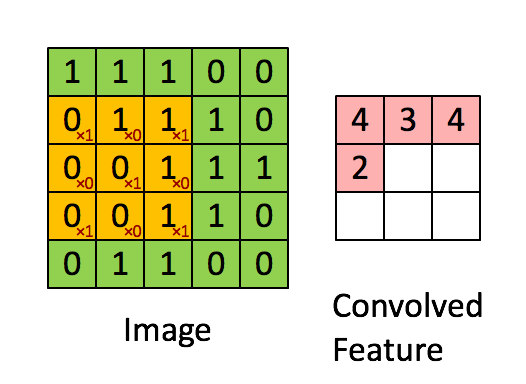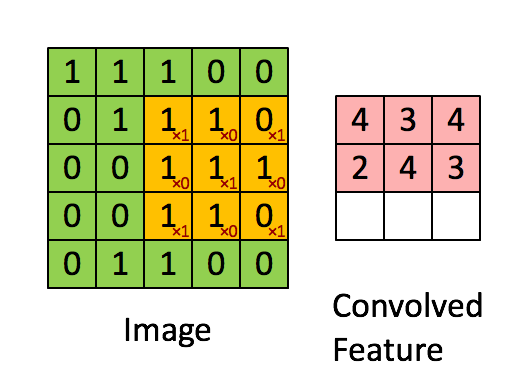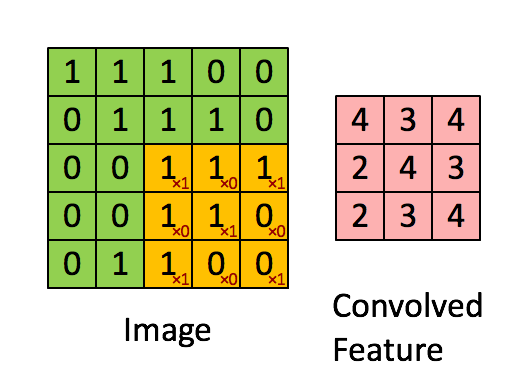
그럼 이 Feature Map 은 Input Image와 비교하면 크기가 작아졌기 때문에 이미지 비교 시 속도가 빨라진다.
속도가 빠른 만큼 원래 정보가 소실된다고 볼 수 있지만, 모든 pixel을 비교하는 게 아닌 특징을 추출하는 작업이기 때문에 그렇다.
그러니까 Feature Detector(Kernel, Filter라고도 표현함)들을 갖고 연산을 하여 이미지의 특징을 추출하는 과정 = Convolution 이라 할 수 있겠다.
5.1.3 CNN 모델
CNN 모델은 컨볼루션 계층(Convolution layer), 풀링 계층(Pooling layer), 일반적인 인공신경망 계층(특징들을 모아 최종 분류하는 곳)으로 구성되어있다.
- 컨볼루션 계층 : 이미지의 특징을 추출하는 역할.
- 풀링 계층 : 여러 특징 중 가장 중요한 특징 하나를 골라냄.
컨볼루션 계층만으로 구성된 모델도 만들 수 있다.
컨볼루션 연산은 이미지를 겹치는 매우 작은 조각으로 쪼개어 필터 기능을 하는 작은 신경망에 적용하는데, 이 매우 작은 조각을 컨볼루션 필터 혹은 커널이라고 한다. 위 gif에서 노란색 부분을 의미한다. 3x3 칸이 한 칸씩(stride = 1) 움직이며 특징을 추출한다.
풀링 계층 : 추출한 특징을 값 하나로 추려서 Feature Map의 크기를 줄여주고 중요 특징을 강조하는 역할.
풀링 역시 일종의 컨볼루션 연산. 필터가 지나갈 때마다 픽셀 묶어서 평균이나 최댓값을 가져오는 간단한 연산으로 이루어짐.

{kind=link}
2x2 최대 풀링을 stride 2로 처리하는 과정. 보통 풀링 윈도우 크기와 스트라이드는 같은 값으로 설정한다.
CNN은 사물 위치가 조금만 치우쳐도 인식하지 못하던 인공 신경망의 문제를 이미지 전체에 필터를 적용해 특징을 추출하는 방식으로 해결한다.
또한, 일반 인공신경망에 비해 필터만 학습하면 되기 때문에 훨씬 계산량이 적다.
5.2 모델 구현하기
이번 예제에서는 다음과 같다.
컨볼루션 -> 풀링 -> 컨볼루션 -> 드롭아웃 -> 풀링 -> 신경망 -> 드롭아웃 -> 신경망
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torchvision import transforms, datasets
USE_CUDA = torch.cuda.is_available()
DEVICE = torch.device("cuda" if USE_CUDA else "cpu")
# 하이퍼파라미터인 epoch 와 batch 사이즈 정해주기
EPOCHS = 40
BATCH_SIZE = 64
# 학습용, 테스트용 데이터셋 불러오기
# transforms를 이용한 전처리는 파이토치 텐서화, 정규화만 진행
train_loader = torch.utils.data.DataLoader(
datasets.FashionMNIST('./.data',
train = True,
download = True,
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307, ), (0.3081,))
])),
batch_size = BATCH_SIZE, shuffle = True
)
test_loader = torch.utils.data.DataLoader(
datasets.FashionMNIST('./.data',
train = False,
download = True,
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307, ), (0.3081, ))
])),
batch_size = BATCH_SIZE, shuffle = True
)
- 📌 찾아 보기
- 갑자기 저번에도 데이터 불러올 때
transforms.Normalize((0.1307,), (0.3081,))을 집어넣었는데 이 숫자가 뭘 의미하는지 궁금해서 찾아봤다.Normalize 할 때 mean, std 값을 넣어준다는데 실제 출력을 해보니 값이 다르게 나왔다. 같은 고민을 한 사람 링크
FashionMNIST 말고 그냥 MNIST 는 1307, 3081이 나온다.
FashionMNIST mean, std 출력해보기
tmp_transform = transforms.Compose([transforms.ToTensor()])
tmp_trainset = datasets.FashionMNIST('./data', train = True, download = True, transform = tmp_transform)
print(list(tmp_trainset.train_data.size()))
print(tmp_trainset.train_data.float().mean()/255)
print(tmp_trainset.train_data.float().std()/255)
MNIST mean, std 출력해보기
tmp_transform = transforms.Compose([transforms.ToTensor()])
tmp_trainset = datasets.MNIST('./data', train = True, download = True, transform = tmp_transform)
print(list(tmp_trainset.train_data.size()))
print(tmp_trainset.train_data.float().mean()/255)
print(tmp_trainset.train_data.float().std()/255)
다시 돌아와서, 지금 만들 CNN 모델 커널 크기 = 5, 컨볼루션 계층 = 2개.
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
# Conv2D(입력 채널 수, 출력 채널 수)
# 흑백이라 색상 채널이 1개 뿐.
# 1개 받아서 10개의 특징 맵 생성하기
self.conv1 = nn.Conv2d(1, 10, kernel_size = 5)
# 10개 받아서 20개 생성하기
self.conv2 = nn.Conv2d(10, 20, kernel_size = 5)
# 컨볼루션 결과로 나온 출력값에 드롭아웃 해주기.
# 이번엔 함수 사용하지 않고 nnDropout2d 모듈 사용해서 인스턴스 만들어보기.
self.drop = nn.Dropout2d()
# 일반 신경망
self.fc1 = nn.Linear(320, 50) # 50은 그냥 임의로 한거임.
self.fc2 = nn.Linear(50, 10) # 10개로 분류할거니까
# 입력부터 출력까지 데이터가 지나가는 길 만들기
def forward(self, x):
# 컨볼루션 계층 거치고, 맥스 풀링 거치게 하기.
# 맥스 풀링 후 relu 활성화 함수 거치기
x = F.relu(F.max_pool2d(self.conv1(x), 2)) # 2 = 커널 크기
x = F.relu(F.max_pool2d(self.conv2(x), 2))
# 일반 신경망은 1차원의 입력을 받기 때문에 펴주야함.
x = x.view(-1, 320)
# 이제 특징들은 다 추출했으니까, 얘를 받아 분류하는 신경망 계층 구성.
x = F.relu(self.fc1(x)) # relu 거치고
x = self.drop(x, training = self.training) # 드롭아웃 해주고
x = self.fc2(x)
return x
출력이 320인 이유
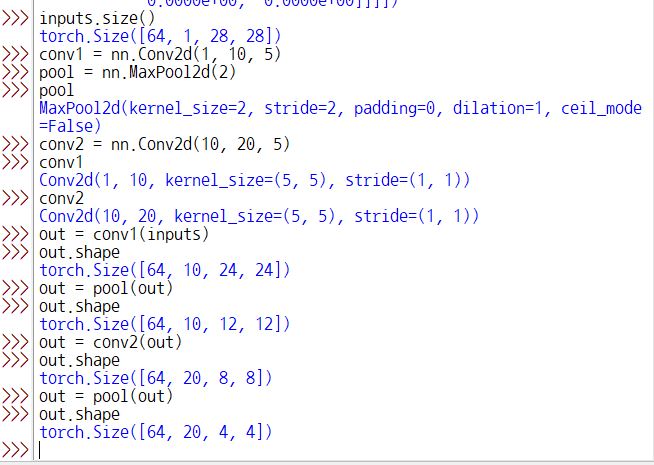 이래서 320(=20x4x4)개임.
이래서 320(=20x4x4)개임.
💡 참고 링크
# 모델 인스턴스 생성
model = Net().to(DEVICE)
# 최적화 알고리즘 = optim.SGD
# momentum = 미분 그래프가 3차 이상의 그래프라 최소점이 2개 이상 생기는 경우
# SGD 에 이전의 이동값을 고려하도록 설계함. (momentum = 관성)
# 지역 최소값에 도달하더라도 앞으로 나아가서 지역 최소값을 탈출할 수 있도록 설정.
optimizer = optim.SGD(model.parameters(), lr = 0.01, momentum = 0.5)
여기부터는 4챕터에서 한 것과 같다.
- 모델을 train 모드로 하고
- 데이터셋에서 배치 가져와 모델에서 출력값 뽑고
- 오차 함수를 이용하여 모델 출력값과 정답 사이 오찻값 계산
- 역전파 알고리즘 실행해주는 backward()로 기울기 계산해서
- 최적화 함수 optimizer.step()으로 구한 기울기값으로 모델 학습 파라미터 갱신
def train(model, train_loader, optimizer, epoch):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(DEVICE), target.to(DEVICE)
optimizer.zero_grad()
output = model(data)
loss = F.cross_entropy(output, target)
loss.backward()
optimizer.step()
if batch_idx % 200 == 0:
print(f"Train Epoch: {epoch} [{batch_idx * len(data)}/{len(train_loader.dataset)} ({100. * batch_idx / len(train_loader):.0f}%)]\tLoss: {loss.item():.6f}")
def evaluate(model, test_loader):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(DEVICE), target.to(DEVICE)
output = model(data)
# 배치 오차를 합산
test_loss += F.cross_entropy(output, target,
reduction = 'sum').item()
# 가장 높은 값을 가진 인덱스가 예측값
pred = output.max(1, keepdim = True)[1]
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
test_accuracy = 100. * correct / len(test_loader.dataset)
return test_loss, test_accuracy
# 모델 실행
for epoch in range(1, EPOCHS + 1):
train(model, train_loader, optimizer, epoch)
test_loss, test_accuracy = evaluate(model, test_loader)
print(f"[{epoch}] Test Loss: {test_loss:.4f}, Accuracy: {test_accuracy:.2f}%")
출력값
Train Epoch: 1 [0/60000 (0%)] Loss: 2.300354
Train Epoch: 1 [12800/60000 (21%)] Loss: 1.227857
Train Epoch: 1 [25600/60000 (43%)] Loss: 0.940719
Train Epoch: 1 [38400/60000 (64%)] Loss: 0.434102
Train Epoch: 1 [51200/60000 (85%)] Loss: 0.492654
[1] Test Loss: 0.1877, Accuracy: 94.41%
Train Epoch: 2 [0/60000 (0%)] Loss: 0.508746
Train Epoch: 2 [12800/60000 (21%)] Loss: 0.360867
Train Epoch: 2 [25600/60000 (43%)] Loss: 0.262731
Train Epoch: 2 [38400/60000 (64%)] Loss: 0.187272
Train Epoch: 2 [51200/60000 (85%)] Loss: 0.297897
[2] Test Loss: 0.1136, Accuracy: 96.34%
...
Train Epoch: 39 [0/60000 (0%)] Loss: 0.075213
Train Epoch: 39 [12800/60000 (21%)] Loss: 0.075232
Train Epoch: 39 [25600/60000 (43%)] Loss: 0.147195
Train Epoch: 39 [38400/60000 (64%)] Loss: 0.042404
Train Epoch: 39 [51200/60000 (85%)] Loss: 0.133474
[39] Test Loss: 0.0320, Accuracy: 98.92%
Train Epoch: 40 [0/60000 (0%)] Loss: 0.051095
Train Epoch: 40 [12800/60000 (21%)] Loss: 0.058751
Train Epoch: 40 [25600/60000 (43%)] Loss: 0.070169
Train Epoch: 40 [38400/60000 (64%)] Loss: 0.184731
Train Epoch: 40 [51200/60000 (85%)] Loss: 0.176196
[40] Test Loss: 0.0328, Accuracy: 98.92%
💡 해당 포스팅은 펭귄브로의 3분 딥러닝, 파이토치맛 교재를 통해 학습한 내용을 정리한 글입니다.