7. 순차적인 데이터를 처리하는 RNN
7.3 Seq2Seq 기계 번역
언어를 다른 언어로 해석해주는 뉴럴 기계 번역
RNN 기반 번역 모델인 Sequence to Sequence : 시퀀스를 입력받아 또 다른 시퀀스 출력.
대표적인 예로 챗봇과 기계 번역 등이 있다.
일반적으로 기계 번역 모델이 이런 능력을 학습하려면 원문과 번역문이 쌍을 이루는 많은 텍스트 데이터(=병렬 말뭉치)가 많이 필요하고, 강력한 GPU, 복잡한 전처리 과정, 긴 학습 시간 등 많은 리소스가 들지만 이번 예제에서는 간소화하여 맛만 보자!
7.3.1 Seq2Seq 개요
Seq2Seq는 다른 역할(외국어 문장 읽고 의미 이해, 외국어 문장 의미 생각하며 한국어로 작성)을 하는 두 개의 RNN을 이어붙인 모델.
이 두 역할을 각각 인코더와 디코더라는 두 RNN에 부여함으로써 번역한다.

7.3.2 인코더
인코더 : 원문의 내용을 학습하는 RNN
위 그림에서처럼 원문 속의 모든 단어를 입력 받아 문장 뜻을 내포하는 하나의 고정 크기 벡터를 생성한다.
이 벡터는 원문의 뜻과 내용을 압축하고 있다고 해서 문맥 벡터라고 한다. 위 그림에서는 ‘student’ 가 입력된 은닉 벡터가 문맥 벡터이다.
📌 오토인코더와 RNN 인코더 차이
오토인코더는 정보를 추려내 차원 수를 줄여주는 것이고, Seq2Seq 모델의 RNN 인코더는 동적인 시계열 데이터를 간단한 형태의 정적인 데이터로 요약하는 것이다.
7.3.3 디코더
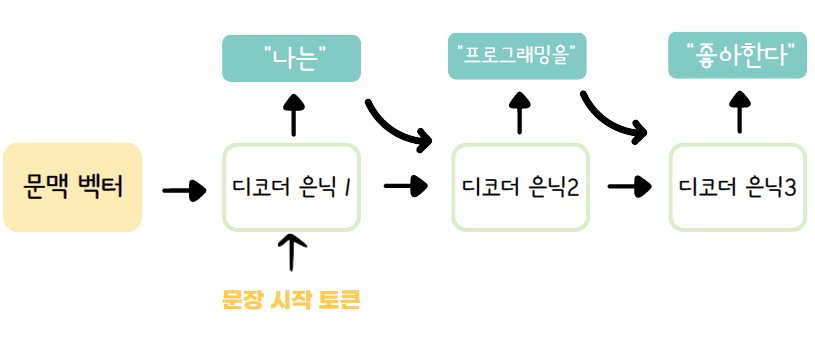 인코더에서 원문 문맥 벡터를 이어받아 번역문 속 토큰을 차례대로 예상한다. 디코더가 예상해낸 모든 토큰과 실제 번역문 사이 오차를 줄여나가는 것이 Seq2Seq 모델이 학습하는 기본 원리이다.
인코더에서 원문 문맥 벡터를 이어받아 번역문 속 토큰을 차례대로 예상한다. 디코더가 예상해낸 모든 토큰과 실제 번역문 사이 오차를 줄여나가는 것이 Seq2Seq 모델이 학습하는 기본 원리이다.
7.3.4 Seq2Seq 모델 구현하기
# 필수 라이브러리 import
import torch
import torch.nn as nn
import random
import matplotlib.pyplot as plt
번역 작업 할 때 보통 단어를 문장의 최소 단위로 생각하고 임베딩을 한다.
이번 예제에서는 영단어 “hello”를 스페인어 ‘holo’로 번역하기 때문에 워드 임베딩이 아닌 글자 단위의 캐릭터 임베딩을 사용한다.
# 데이터셋 속 토큰 종류 수
vocab_size = 256 # 총 아스키 코드 개수
# 번역할 원문과 번역문을 아스키 코드 배열로 정의 -> 파이토치 텐서로 변경
x_ = list(map(ord, "hello"))
y_ = list(map(ord, "hola"))
x = torch.LongTensor(x_)
y = torch.LongTensor(y_)
# 모델 클래스 정의
class Seq2Seq(nn.Module):
def __init__(self, vocab_size, hidden_size):
super(Seq2Seq, self).__init__()
self.n_layers= 1 # 은닉 벡터 층
self.hidden_size = hidden_size # 생성되는 은닉 벡터 차원값
# 임베딩 함수 정의
# 임베딩 차원 값 따로 안 정하고 hidden_size를 임베딩된 토큰의 차원값으로 정의
# 실전에서는 원문과 번역문의 문자 체계가 완전 다른 경우를 대비해,
# 원문용 임베딩과 번역문용 임베딩 따로 만들어야함.
# 지금은 그냥 둘다 아스키 코드로 나타내기 때문에 하나만 만들어줘도 무방.
self.embedding = nn.Embedding(vocab_size, hidden_size)
self.encoder = nn.GRU(hidden_size, hidden_size)
self.decoder = nn.GRU(hidden_size, hidden_size)
# 디코더가 번역문의 다음 토큰 예상해내는 작은 신경망 하나 더 생성
self.project = nn.Linear(hidden_size, vocab_size)
def forward(self, inputs, targets):
initial_state = self._init_state() # 첫 번째 은닉 벡터
embedding = self.embedding(inputs).unsqueeze(1) # hello를 구성하는 모든 문자 임베딩
# encoder_state = 문맥 벡터 / decoder_state = 디코더의 첫 번째 은닉 벡터
encoder_output, encoder_state = self.encoder(embedding, initial_state)
decoder_state = encoder_state
decoder_input = torch.LongTensor([0])
# 디코더는 문장 시작 토큰인 아스키 코드 0번을 이용하여 "hola"의 "h" 토큰을 예측.
# 다음 반복에서는 'h'를 이용해 'o'를 예측해야함. -> for문으로 구현
outputs = []
for i in range(targets.size()[0]):
# 첫 번째 토큰과 인코더 문맥 벡터 동시에 입력 받음.
decoder_input = self.embedding(decoder_input).unsqueeze(1)
decoder_output, decoder_state = self.decoder(decoder_input, decoder_state)
# 결과값 다시 입력하고, 출력값이 마지막 마지막 층인 Softmax 층 거치면
# 번역문 다음 예상 글자가 나온다.
# 예상 결과 outputs 텐서에 저장해 오차 계산할 때 사용.
projection = self.project(decoder_output)
outputs.append(projection)
# 티처 포싱을 이용한 디코더 입력 갱신
decoder_input = torch.LongTensor([targets[i]])
# outputs = 모든 토큰에 대한 결과값들의 배열
outputs = torch.stack(outputs).squeeze()
return outputs
# 첫 번째 은닉 벡터 정의하는 함수
def _init_state(self, batch_size = 1):
# parameters() : 신경망 모듈의 가중치 정보를 반복자 형태로 반환
# 얘가 생성하는 원소들은 실제 신경망의 가중치 텐서를 지닌 객체.
weight = next(self.parameters()).data # 첫 번째 가중치 텐서 추출
# new() 함수 사용해 텐서로 변환 후, zero_()로 텐서 내 모든 값 0으로 초기화
# 첫 번째 은닉벡터는 모든 특성값이 0인 벡터로 설정됨.
return weight.new(self.n_layers, batch_size, self.hidden_size).zero_()

디코더가 번역문의 첫 번째 토큰을 예상하려면, 인코더의 문맥 벡터와 문장 시작 토큰을 입력 데이터로 받아야한다.
- 입력 시작 토큰 : 실제 문장에는 나타나지 않지만, 디코더가 정상적으로 작동할 수 있도록 인위적으로 넣은 토큰. 말 그대로 디코더에 문장의 시작을 알리기 위함이며, 아스키값으로 공백 문자(null)을 뜻하는 0으로 설정.
seq2seq 모델은 디코더가 예측한 토큰을 다음 반복에서 입력될 토큰으로 갱신해주는 것이 정석이다. 하지만 학스이 아직 되지 않은 상태의 모델은 잘못된 예측 토큰을 입력으로 사용할 확률이 높다. 잘못된 토큰이 사용되면 학습이 더뎌진다.
이를 방지하기 위한 방법 중 대표적인 것이 티처 포싱(teacher forcing) 이다.
- 티처 포싱 : 디코더 학습 시 실제 번역문의 토큰을 디코더의 전 출력값 대신 입력으로 사용해 학습을 가속하는 방법.
# 오차 함수와 최적화 알고리즘 정의
seq2seq = Seq2Seq(vocab_size, 16)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(seq2seq.parameters(), lr = 1e-3)
# 모델 학습 Epoch = 1000
log = []
for i in range(1000):
prediction = seq2seq(x, y)
loss = criterion(prediction, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
loss_val = loss.data
log.append(loss_val)
if i % 100 == 0:
print(f"\n 반복:{i} 오차:{loss_val.item()}")
_, top1 = prediction.data.topk(1, 1)
print([chr(c) for c in top1.squeeze().numpy().tolist()])
출력값
반복:0 오차:5.719714164733887
['ú', '>', '{', "'"]
반복:100 오차:2.03080677986145
['h', 'l', 'l', 'l']
반복:200 오차:0.5871451497077942
['h', 'o', 'l', 'a']
반복:300 오차:0.30315762758255005
['h', 'o', 'l', 'a']
반복:400 오차:0.20184971392154694
['h', 'o', 'l', 'a']
반복:500 오차:0.14708589017391205
['h', 'o', 'l', 'a']
반복:600 오차:0.11225750297307968
['h', 'o', 'l', 'a']
반복:700 오차:0.0890098288655281
['h', 'o', 'l', 'a']
반복:800 오차:0.07269123941659927
['h', 'o', 'l', 'a']
반복:900 오차:0.06066729128360748
['h', 'o', 'l', 'a']
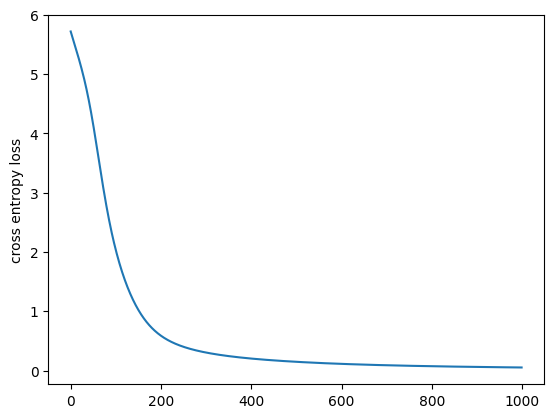
오차를 matplotlib을 통해 시각화하면 아래와 같다.
# 오차 시각화
plt.plot(log)
plt.ylabel("cross entropy loss")
plt.show()
💡 해당 포스팅은 펭귄브로의 3분 딥러닝, 파이토치맛 교재를 통해 학습한 내용을 정리한 글입니다.