9. 경쟁하며 학습하는 GAN
9.1 GAN 기초
GAN(=Generative Adversarial Network) 직역하면 적대적 생성 신경망이다. 단어를 하나씩 뜯어서 이해하면 편하다.
- Generative : GAN은 생성을 하는 모델이다. CNN, RNN과는 달리 GNN은 새로운 이미지나 음성을 창작하도록 고안되었다.
- Adversarial : GAN은 적대적으로 학습한다. 가짜 이미지를 생성하는 생성자와 이미지의 진위를 판별하는 판별자가 번갈아 학습하며 경쟁적으로 학습을 진행한다.
- Network : GAN은 인공 신경망 모델이다. 생성자, 판별자가 모두 신경망으로 되어있다.
GAN은 비지도학습 방식이다. 비지도학습이 미래지향적이라는 평가를 받는 이유는 대부분의 데이터에는 정답(label)이 없기 때문이다. 비지도학습은 사람의 손길을 최소화하며 학습할 수 있다.
9.1.1 생성자와 판별자
- 생성자 : 무작위 텐서로부터 여러 가지 형태의 가짜 이미지를 생성.
- 판별자 : 진짜 이미지와 가짜 이미지를 구분.
학습이 진행되며 생성자는 판별자를 속이기 위해 점점 정밀한 가짜 이미지를 생성하고, 판별자는 학습 데이터에서 가져온 진짜 이미지와 생성자가 만든 가짜 이미지를 점점 더 잘 구별하게 된다.
💡 참고 링크 : GAN의 기초
9.2. GAN으로 새로운 패션 아이템 생성하기
9.2.1 학습 준비
# 필수 라이브러리 import
import os
import torch
import torchvision
import torch.nn as nn
import torch.optim as optim
from torchvision import transforms, datasets
from torchvision.utils import save_image
import matplotlib.pyplot as plt
# 하이퍼파라미터
EPOCHS = 500
BATCH_SIZE = 100
USE_CUDA = torch.cuda.is_available()
DEVICE = torch.device("cuda" if USE_CUDA else "cpu")
print("다음 장치를 사용합니다: ", DEVICE)
출력값
다음 장치를 사용합니다: cpu
# 학습 데이터셋 가져오기
# Fashion MNIST 데이터셋
trainset = datasets.FashionMNIST('./.data',
train = True,
download = True,
transform = transforms.Compose([
transforms.ToTensor(), # 텐서로 바꿔주기
transforms.Normalize((0.5,), (0.5,)) # 정규화
]))
train_loader = torch.utils.data.DataLoader(
dataset = trainset,
batch_size = BATCH_SIZE,
shuffle = True
)
9.2.2 생성자와 판별자 구현
이제까지는 nn.Module클래스를 상속받는 클래스로 정의했기 때문에 모델의 복잡한 동작들을 함수로 정의 가능했다. 하지만 이번 생성자, 판별자는 가독성을 위해 최대한 간단하게 만들고자 한다.
Sequential 클래스로 신경망을 이루는 각 층에서 수행할 연산들을 입력받아 차례로 실행하고자 한다. -> __init__()과 forward() 함수를 동시에 정의.
# 생성자(Generator)
G = nn.Sequential(
nn.Linear(64, 256),
nn.ReLU(),
nn.Linear(256, 256),
nn.ReLU(),
nn.Linear(256, 784), # 결과값이 Fashion MINST 이미지와 같은 차원의 텐서가 되어야함.
nn.Tanh() # 탄젠트 함수 생각하면됨. 값을 -1~1 사이로 압축해줌.
)
판별자에서는 ReLU가 아니라 Leaky ReLU 활성화 함수를 사용한다.
Leaky ReLU활성화 함수는 약간의 음의 기울기도 다음 층에 전달하는 역할을 하는데, 이렇게 하면 판별자에서 계산된 기울기가 0 대신 약한 음수로 전환되며 생성자에 더 강하게 전달되기 때문이다.
생성자가 학습하기 위해 판별자로부터 기울기롤 효과적으로 전달받아야 하기 때문에 중요하다!

# 판별자(Discriminator)
D = nn.Sequential(
nn.Linear(784, 256),
nn.LeakyReLU(0.2),
nn.Linear(256, 256),
nn.LeakyReLU(0.2),
nn.Linear(256, 1), # 진짜/가짜 로 결정이 되기 떄문에 최종 출력값 = 1
nn.Sigmoid()
)
9.2.3 GAN 학습 구현
생성자와 판별자 학습에 쓰일 오차 함수와 최적화 알고리즘을 각각 정의해준다.
- 오차 함수 : 레이블이 가짜/진짜 2가지 뿐이므로 BCE(이진 교차 엔트로피)를 사용.
- 최적화 함수 : Adam (제일 무난하고 빠르다!)
# 모델 가중치 지정 장치에 보내기
D = D.to(DEVICE)
G = G.to(DEVICE)
# 오차 함수 : 진짜/가짜 두 종류니까 BCE
# 최적화 함수 : Adam
criterion = nn.BCELoss()
d_optimizer = optim.Adam(D.parameters(), lr = 0.002)
g_optimizer = optim.Adam(G.parameters(), lr = 0.002)
# 학습시키는 반복문 시작
total_step = len(train_loader)
for epoch in range(EPOCHS):
for i, (images, _) in enumerate(train_loader):
images = images.reshape(BATCH_SIZE, -1).to(DEVICE) # batch 사이즈로 텐서 크기 바꿔주기
### 1. '진짜'와 '가짜' 레이블 생성
# 생성자가 만든 데이터 = zeros() 로 0으로 채워서 라벨링 해주기
# Fashion MINST 데이터 = ones() 로 1로 채워서 라벨링 해주기
real_labels = torch.ones(BATCH_SIZE, 1).to(DEVICE)
fake_labels = torch.zeros(BATCH_SIZE, 1).to(DEVICE)
### 2. 판별자가 진짜 이미지를 진짜로 인식하는 오차를 예산
outputs = D(images) # 실제 이미지 -> 판별자 신경망 결과값
d_loss_real = criterion(outputs, real_labels) # 진짜 레이블간의 오차 계산
real_score = outputs
### 3. 생성자 동작 정의
# 생성자는 정규분포로부터 생성한 무작위 텐서 -> 실제 이미지와 차원 같은 텐서 배출
z = torch.randn(BATCH_SIZE, 64).to(DEVICE)
fake_images = G(z)
### 4. 판별자가 가짜 이미지를 가짜로 인식하는 오차를 계산
# 생성자 이미지(fake_images) -> 판별자에 입력 -> 오차 계산
outputs = D(fake_images)
d_loss_fake = criterion(outputs, fake_labels)
fake_score = outputs
### 5. 진짜와 가짜 이미지를 갖고 낸 오차를 더해서 판별자의 오차 계산
d_loss = d_loss_real + d_loss_fake
# 역전파로 판별자 모델 학습 진행 -> 판별자 학습!
d_optimizer.zero_grad()
g_optimizer.zero_grad()
d_loss.backward()
d_optimizer.step()
### 6. 생성자 학습 차례
# 생성자가 판별자를 속였는지에 대한 오차를 계산
fake_images = G(z)
outputs = D(fake_images) # 생성자의 결과물을 다시 판별자에 입력시켜
g_loss = criterion(outputs, real_labels) # 결과물과 1 사이 오차 최소화하는 방식으로 학습 진행
### 7. 역전파로 생성자 학습 진행
d_optimizer.zero_grad()
g_optimizer.zero_grad()
g_loss.backward()
g_optimizer.step()
### 8. 학습 진행 알아보기
# d_loss = 판별자 오차, g_loss = 생성자 오차
# D(x) = 진짜를 진짜로 인식한 '정확도'
# D(G(z)) = 가짜를 진짜로 인식한 정확도
print('Epoch [{}/{}], d_loss: {:.4f}, g_loss: {:.4f}, D(x): {:.2f}, D(G(z)): {:.2f}'
.format(epoch, EPOCHS, d_loss.item(), g_loss.item(),
real_score.mean().item(), fake_score.mean().item()))
학습 시간이 너무 오래 걸려서 학습 결과는 책 결과를 참고하였다.
Epoch [0/500], d_loss: 0.0353, g_loss: 4.5795, D(x): 0.99, D(G(z)): 0.02
Epoch [1/500], d_loss: 0.0207, g_loss: 4.8400, D(x): 0.99, D(G(z)): 0.01
Epoch [2/500], d_loss: 0.0208, g_loss: 6.7210, D(x): 0.99, D(G(z)): 0.01
...
Epoch [497/500], d_loss: 1.0776, g_loss: 1.4313, D(x): 0.64, D(G(z)): 0.33
Epoch [498/500], d_loss: 1.2960, g_loss: 1.1681, D(x): 0.60, D(G(z)): 0.40
Epoch [499/500], d_loss: 0.7900, g_loss: 1.6450, D(x): 0.72, D(G(z)): 0.27
# 학습 끝난 생성자 결과물 확인
z = torch.randn(BATCH_SIZE, 64).to(DEVICE)
fake_images = G(z)
for i in range(10):
fake_images_img = np.reshape(fake_images.data.cpu().numpy()[i],(28, 28))
plt.imshow(fake_images_img, cmap = 'gray')
plt.show()
9.2.4 결과물 시각화
z = torch.randn(BATCH_SIZE, 64).to(DEVICE)
fake_images = G(z)
for i in range(10):
fake_images_img = np.reshape(fake_images.data.cpu().numpy()[i], (28, 28))
plt.imshow(fake_images_img, cmap = 'gray')
plt.show()

9.3 cGAN으로 생성 제어하기
GAN가 더 쓸모 있으려면 무작위 생성보다는 사용자가 원하는 이미지를 생성하는 기능을 제공해야한다.
9.3.1 cGAN으로 원하는 이미지 생성하기
앞에서 한 GAN 모델은 ‘패션 아이템 종류 중 무엇을 생성하라’라는 로직이 없었다.
무작위 벡터 입력 -> 무작위 패션 아이템 출력
즉, 사용자가 원하는 패션 아이템을 생성하는 능력이 없다. 이를 보완해 출력할 아이템의 종류를 사용자로부터 입력받아 그에 해당하는 이미지를 생성하는 모델이 조건부 GAN(=cGAN).
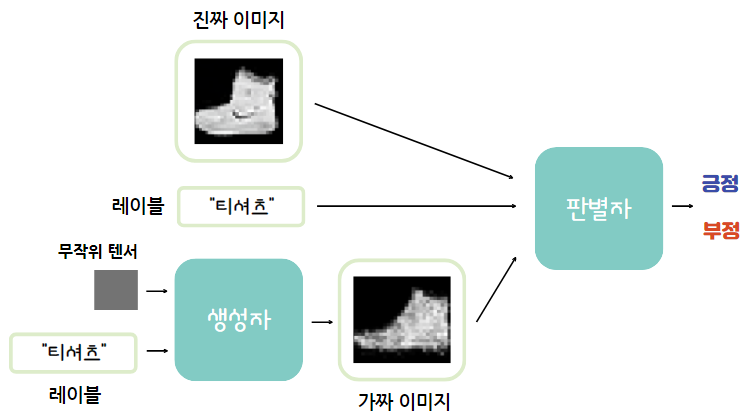
필요한 라이브러리 임포트, 하이퍼파라미터 설정, 데이터 로딩 부분은 GAN과 같다.
9.3.2 조건부 생성자와 판별자
# 생성자 (Generator)
class Generator(nn.Module):
def __init__(self):
super().__init__()
self.embed = nn.Embedding(10, 10)
self.model = nn.Sequential(
nn.Linear(110, 256), # 왜 110개? -> 100 + 10(레이블 정보)
# nn.LeakyReLU(negative_slope=0.01, inplace=False)
# inplace = True -> 입력을 복사하지 않고 바로 조작한다는 뜻
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(256, 512),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 1024),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(1024, 784),
nn.Tanh()
)
def forward(self, z, labels): # 입력과 레이블 정보까지 2가지 입력 받음.
# 배치x1 크기의 배치x10의 연속적인 텐서로 전환
c = self.embed(labels)
# cat() : 두 벡터를 두 번째 인수 차원에 대해 이어붙이는 연산 실행.
x = torch.cat([z, c], 1)
return self.model(x)
💡 참고 링크 : nn.Embedding()
레이블이 주어졌을때 가짜인 확률과 진짜인 확률을 추정한다.
# 판별자 (Discriminator)
class Discriminator(nn.Module):
def __init__(self):
super().__init__()
self.embed = nn.Embedding(10, 10)
# 성능 늘리기 위해 드롭아웃 계층 2개 더 추가.
self.model = nn.Sequential(
nn.Linear(794, 1024), # 784 + 10(레이블 정보 전달)
nn.LeakyReLU(0.2, inplace=True),
nn.Dropout(0.3),
nn.Linear(1024, 512),
nn.LeakyReLU(0.2, inplace=True),
nn.Dropout(0.3),
nn.Linear(512, 256),
nn.LeakyReLU(0.2, inplace=True),
nn.Dropout(0.3),
nn.Linear(256, 1),
nn.Sigmoid()
)
def forward(self, x, labels):
c = self.embed(labels)
x = torch.cat([x, c], 1)
return self.model(x)
9.3.3 cGAN 학습 구현
# 모델 인스턴스를 만들고 모델의 가중치를 지정한 장치로 보내기
D = Discriminator().to(DEVICE)
G = Generator().to(DEVICE)
# 오차 함수,최적화 함수 앞과 동일
criterion = nn.BCELoss()
d_optimizer = optim.Adam(D.parameters(), lr =0.0002)
g_optimizer = optim.Adam(G.parameters(), lr =0.0002)
total_step = len(train_loader)
for epoch in range(EPOCHS):
# 그냥 GAN에선 라벨이 필요 없어 (images, _) 였는데, 이번엔 받아서 사용.
for i, (images, labels) in enumerate(train_loader):
images = images.reshape(BATCH_SIZE, -1).to(DEVICE)
# 진짜/가짜 레이블 생성
real_labels = torch.ones(BATCH_SIZE, 1).to(DEVICE)
fake_labels = torch.zeros(BATCH_SIZE, 1).to(DEVICE)
# 판별자가 진짜 이미지를 진짜로 인식하는 오차 계산 (데이터셋 레이블 입력)
labels = labels.to(DEVICE)
outputs = D(images, labels)
d_loss_real = criterion(outputs, real_labels)
real_score = outputs
# 무작위 텐서 생성 = g_label
z = torch.randn(BATCH_SIZE, 100).to(DEVICE)
g_label = torch.randint(0, 10, (BATCH_SIZE,)).to(DEVICE)
fake_images = G(z, g_label) # 무작위 텐서와 입력 z 로 가짜 이미지 생성
# 판별자에게 가짜 이미지 입력.
# outputs = (가짜 이미지, 그에 대한 레이블값)를 판별한 값
outputs = D(fake_images, g_label)
d_loss_fake = criterion(outputs, fake_labels) # 오차 계산
fake_score = outputs
# loss_real = 진짜 이미지 넣었을 때 오차
# loss_fake = 가짜 이미지 넣었을 때 오차
d_loss = d_loss_real + d_loss_fake # 총 오차
# 역전파로 판별자 학습 진행
d_optimizer.zero_grad()
g_optimizer.zero_grad()
d_loss.backward()
d_optimizer.step()
# 아까 생성해둔 z와 g_label로 다시 이미지 생성 => 판별자 속였나?
# 생성자, 판별자 둘 다 g_label을 라벨로 받기
fake_images = G(z, g_label)
outputs = D(fake_images, g_label)
g_loss = criterion(outputs, real_labels)
# 못 속인 만큼 생성자 학습 진행
d_optimizer.zero_grad()
g_optimizer.zero_grad()
g_loss.backward()
g_optimizer.step()
print('이폭 [{}/{}] d_loss:{:.4f} g_loss: {:.4f} D(x):{:.2f} D(G(z)):{:.2f}'
.format(epoch,
EPOCHS,
d_loss.item(),
g_loss.item(),
real_score.mean().item(),
fake_score.mean().item()))
마찬가지로 출력 결과는 책의 내용을 가져왔다.
이폭 [0/300] d_loss:0.3160 g_loss: 6.8871 D(x):0.89 D(G(z)):0.04
이폭 [1/300] d_loss:0.5910 g_loss: 3.9762 D(x):0.87 D(G(z)):0.19
이폭 [2/300] d_loss:0.3091 g_loss: 4.8783 D(x):0.92 D(G(z)):0.08
이폭 [3/300] d_loss:0.1595 g_loss: 4.3155 D(x):0.95 D(G(z)):0.06
이폭 [4/300] d_loss:0.5849 g_loss: 3.0070 D(x):0.78 D(G(z)):0.13
...
이폭 [295/300] d_loss:1.2423 g_loss: 1.0166 D(x):0.63 D(G(z)):0.43
이폭 [296/300] d_loss:1.3765 g_loss: 0.9225 D(x):0.49 D(G(z)):0.44
이폭 [297/300] d_loss:1.2616 g_loss: 0.8626 D(x):0.56 D(G(z)):0.45
이폭 [298/300] d_loss:1.2170 g_loss: 0.8461 D(x):0.57 D(G(z)):0.43
이폭 [299/300] d_loss:1.1471 g_loss: 1.2162 D(x):0.60 D(G(z)):0.38
9.3.4 결과물 시각화
torch.full(텐서 크기, 텐서 원소 초기화할 값) : 새로운 텐서를 만드는 함수.
# 만들고 싶은 아이템 생성하고 시각화하기
item_number = 9 # 아이템 번호 : 부츠
z = torch.randn(1, 100).to(DEVICE) # 배치 크기 1
# g_label = 지정한 아이템 번호
g_label = torch.full((1,), item_number, dtype=torch.long).to(DEVICE)
sample_images = G(z, g_label) # 이미지 생성
sample_images_img = np.reshape(sample_images.data.cpu().numpy()
[0],(28, 28))
plt.imshow(sample_images_img, cmap = 'gray')
plt.show()

9번 부츠 이미지가 잘 생성되었음을 확인할 수 있다!
💡 해당 포스팅은 펭귄브로의 3분 딥러닝, 파이토치맛 교재를 통해 학습한 내용을 정리한 글입니다.